
memoQ 統計機能を掘り下げる
日々memoQを使用してプロジェクトのハンドリングを行っている筆者ですが、翻訳会社でPMを担当している方々にとって、使用頻度の多い機能といえばファイルの解析機能ではないでしょうか。
翻訳支援ツール(CATツール)には翻訳対象のファイルのボリュームやマッチ率を把握するための解析機能がついています。高い機能性を誇るCATツールのmemoQ。解析機能にも色々な設定がありますが、なんとなく初期設定のままで使ってしまっている人も意外と多いのではないでしょうか。(筆者もそうでした..)
今回は、memoQの解析機能について、掘り下げていきたいと思います。うまく使いこなせば、見積もりの精度アップや作業の効率化に繋がる機能があるかもしれません。是非最後まで読んでみてください。

解析結果を理解しよう
プロジェクトホームで、解析したいファイルを選択し、統計ボタンを押します。
統計画面が表示されます。
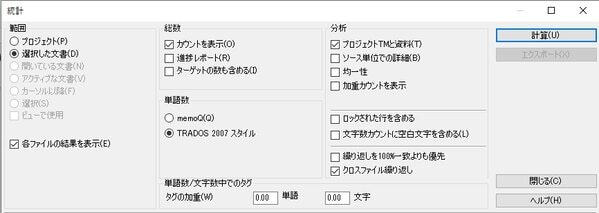
エリアごとにみていきましょう。
範囲
解析をかける範囲を指定します。
- プロジェクト
プロジェクトに含まれている全てのファイルを解析します
- 選択した文書
選択されたファイルのみ解析します
- 開いている文書
エディタ上で開いているファイルを全て解析します
- アクティブな文書
編集中のファイルを解析します
- カーソル以降
編集中のファイルで、カーソル以降を解析します
- 選択
選択したセグメントのみ解析します
- ビューで使用
ビューを解析します
総数
- カウントを表示
翻訳メモリの解析結果とは別に、セグメント・ワード・文字の総数を表示します
- 進捗レポート
解析範囲のなかで、確定済み・編集中・未作業等のセグメントをステータス別にカウントします
- ターゲットの数も含める
訳文セグメントの文字数/ワード数をカウントします
単語数
- memoQ
memoQのカウント基準で解析します(通常はこちらにチェックを入れます)
- TRADOS 2007 スタイル
SDL Trados 2007のカウント基準で解析します
単語数/文字数中でのタグ
- タグの加重
翻訳対象がタグを多数含んでおり、タグもカウントに含めたい場合などに使用します。例えば「0.25単語」とすると、1タグ=0.25ワードとカウントされます。「2文字」とすると、1タグ=2文字としてカウントされます
分析
- プロジェクトTMと資料
プロジェクトに設定されているすべての翻訳メモリやLiveDocsを使ってマッチ率を解析します
- ソース単位での詳細
翻訳メモリやLiveDocsごとにマッチ率を解析します
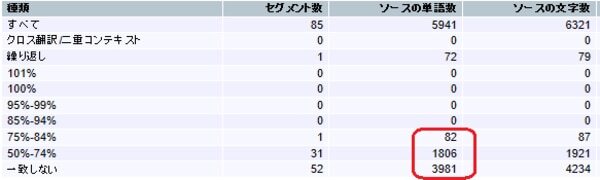
- 均一性
解析対象の中の類似セグメントのマッチ率を結果に含めます(インターナルファジー)
[均一性]チェック無し:
[均一性]チェックあり:
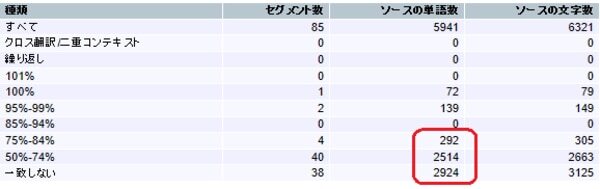
原文の中にどれくらい似たようなセグメントがあるか知りたい場合に使う機能です。
- プロジェクト翻訳メモリを作成
プロジェクトに設定されている翻訳メモリやLiveDocsの中から、マッチしたセグメントを集めて新しい翻訳メモリを作成します
- 加重カウント表示
文字/ワード数の横にワークロードを表示します。ワークロードを計算する際の傾斜は[加重]に表示されます。(変更することも可能)
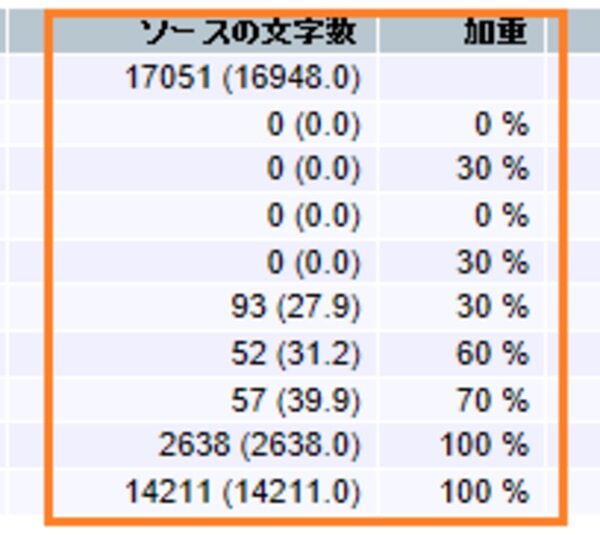
- ロックされた行を含める
ロックされたセグメントもカウントします
- 文字数カウントに空白文字を含める
スペースもカウントします
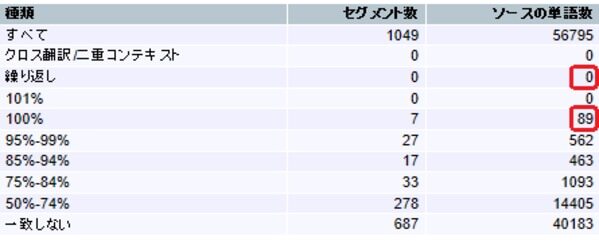
- 繰り返しを100%一致よりも優先
「繰り返し」且つ「100%マッチ」のセグメントがある場合、「繰り返し」としてカウントします。具体的には、以下の条件に当てはまるセグメントが「繰り返し」としてカウントされます。
・繰り返しのセグメントである
・2回目以降の繰り返しである
・TMマッチ率が100%である
[繰り返しを100%一致よりも優先]チェック無し
[繰り返しを100%一致よりも優先]チェックあり
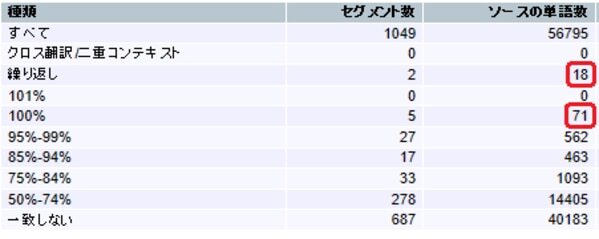
100%マッチのセグメントのうち、繰り返しである18セグメントが、「繰り返し」としてカウントされています。
- クロスファイル繰り返し
複数のファイル間での繰り返しを表示します
まとめ
解析結果の項目を見ていきましたが、いかがでしょうか。設定をうまく利用することで、様々なケースに対応できると思います。
- 翻訳メモリごとに、ワークロードを出したい
- 複数ファイルを一人の翻訳者で作業するので、ファイル間の類似・繰り返しを出したい
- プロジェクトを軽くするために、複数の大きな翻訳メモリからプロジェクト用のメモリを作りたい
- プロジェクト全体の進捗が見たい
など、様々なシーンで役に立つこと間違いなしの統計機能。今回の記事をきっかけに、少しでも活かしていただければ幸いです。
川村インターナショナルのサービス
川村インターナショナルでは、翻訳支援ツールを導入予定あるいは導入済みのお客様を対象とした「翻訳支援ツール導入支援」や、自社の情報資産を活用した「翻訳メモリ・用語集作成」などの翻訳業務効率化につながる「言語資産データ作成サービス」を提供しております。
機械翻訳の導入を検討している、翻訳業務を効率化したい、という方はお気軽にお問い合わせください。







